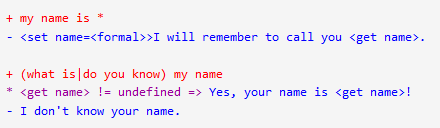
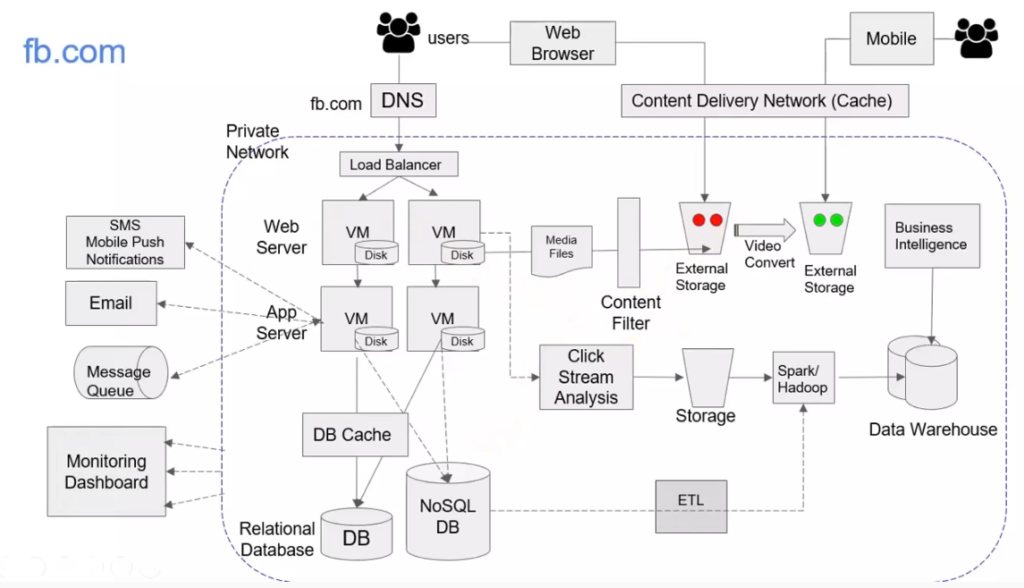
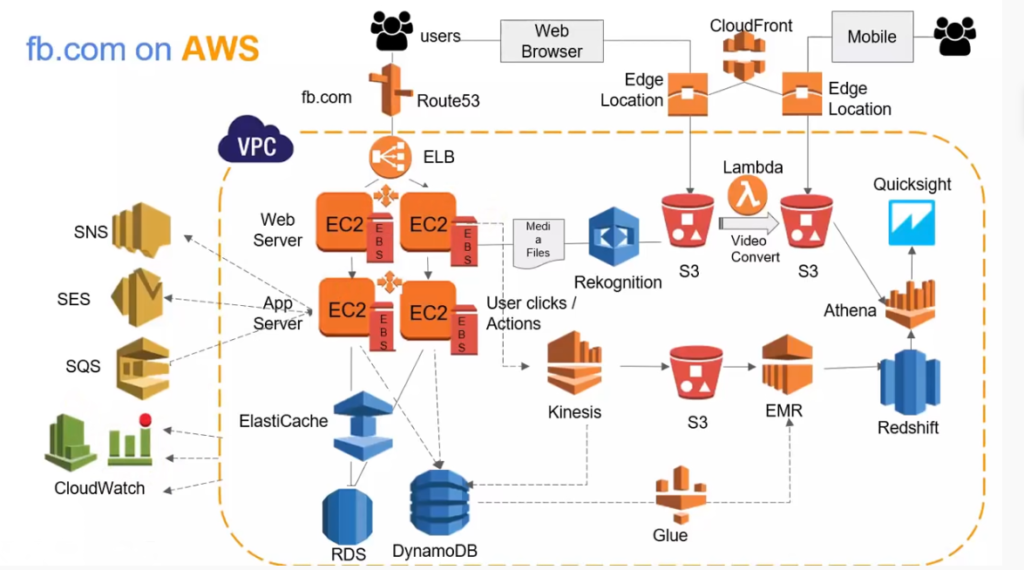
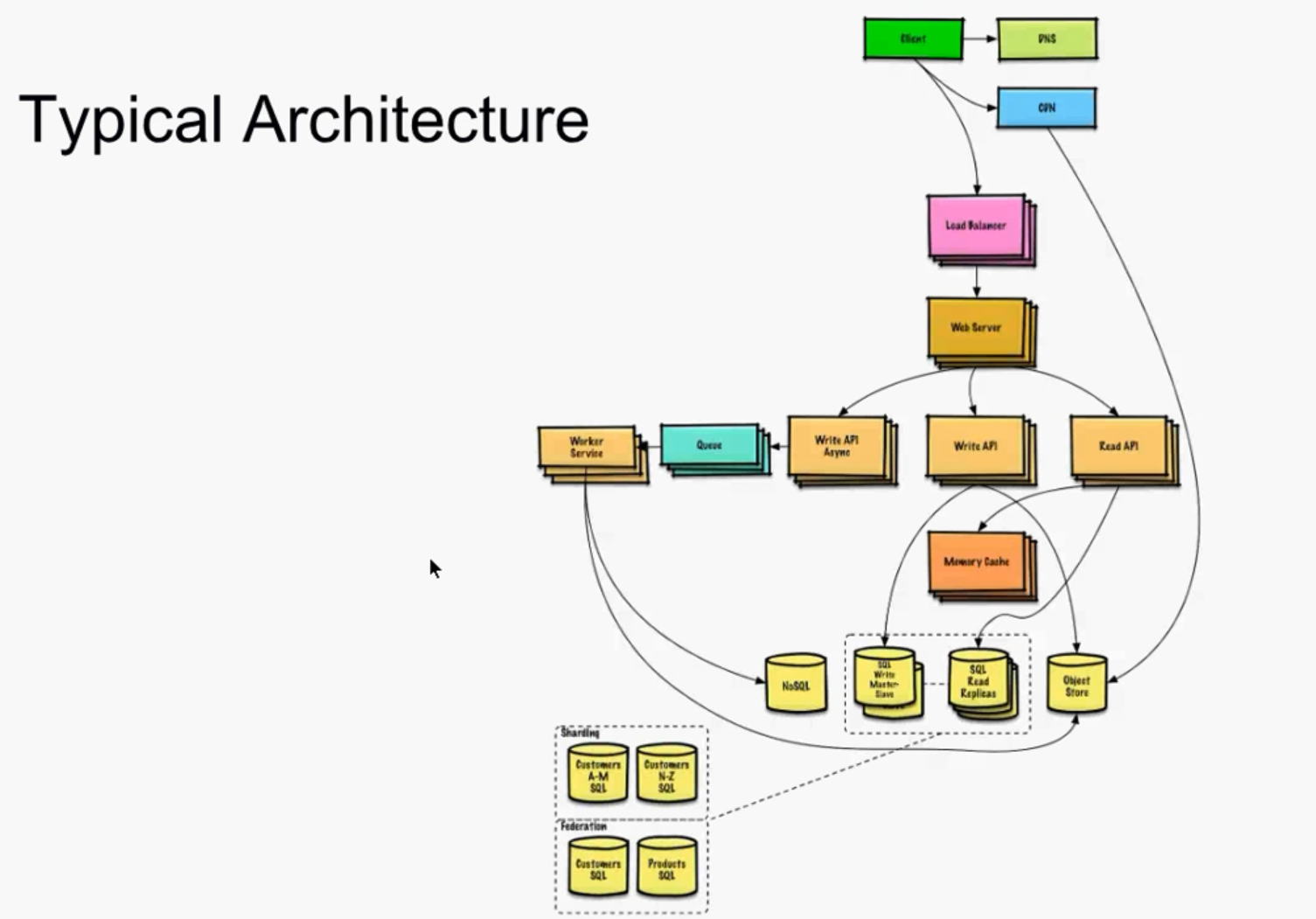
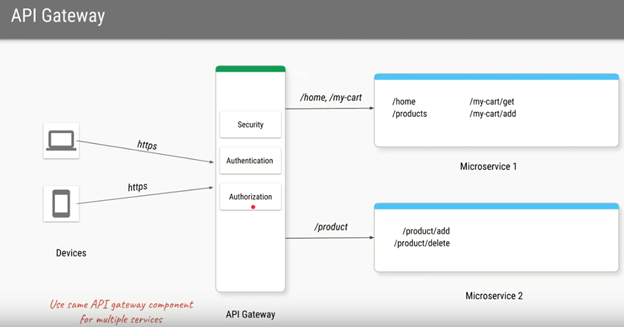
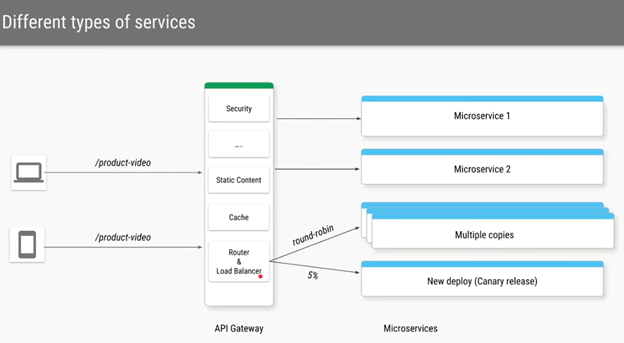
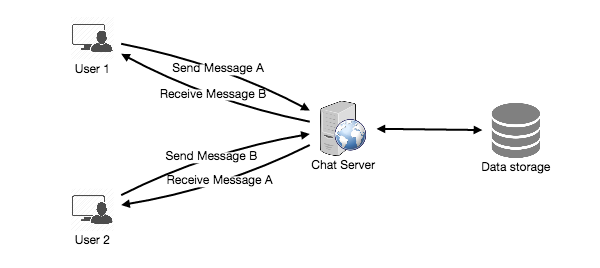
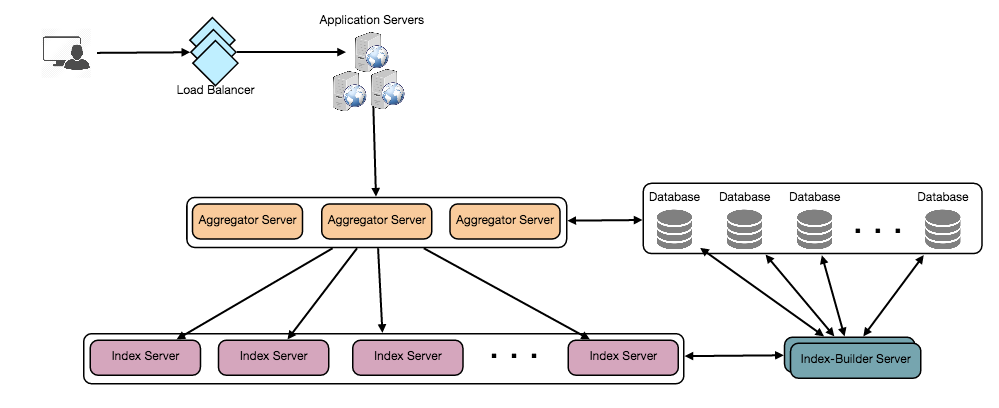
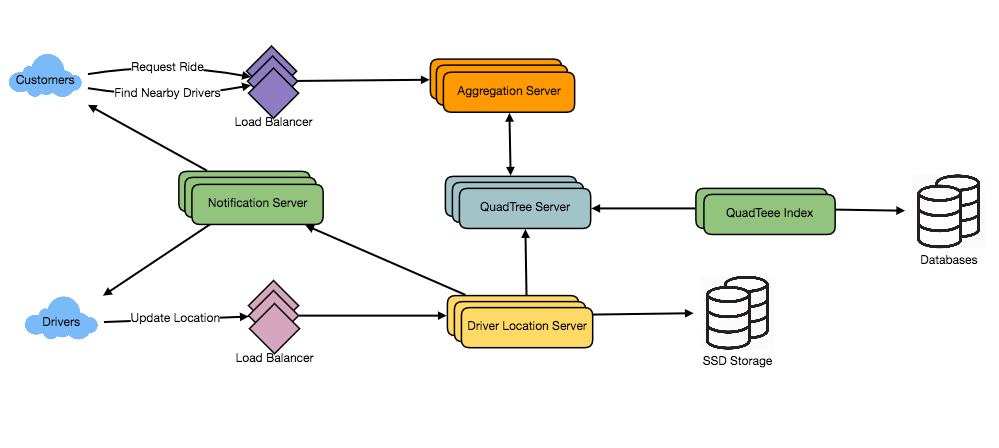
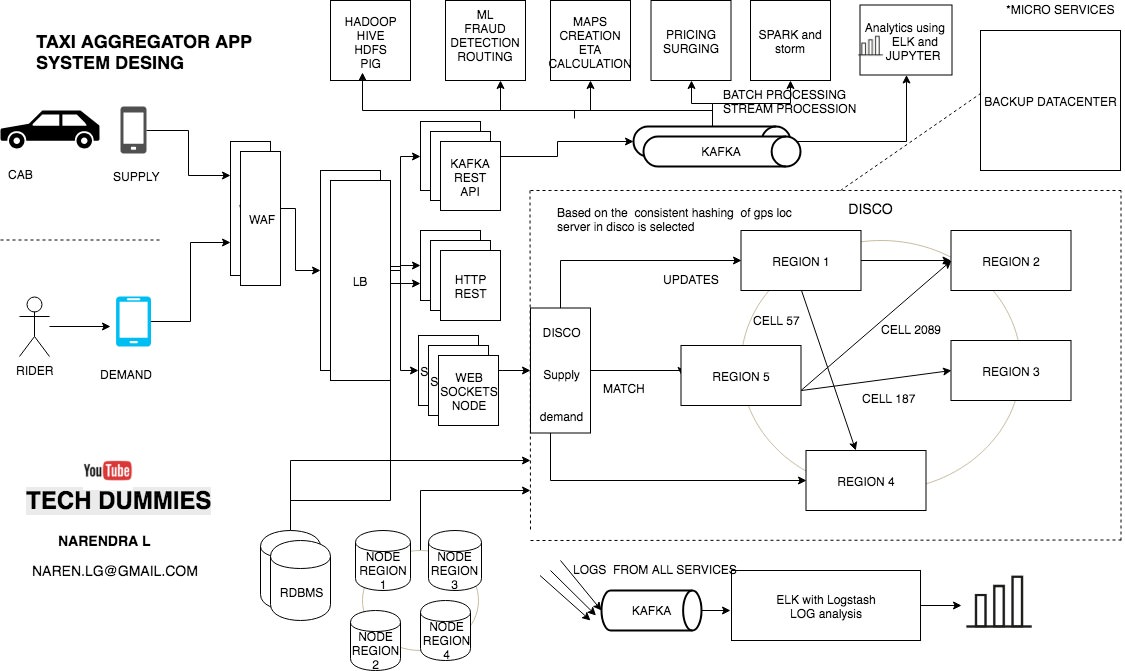
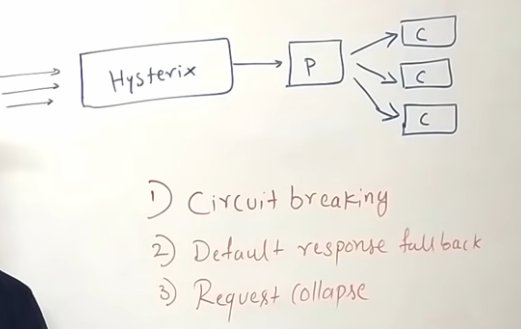
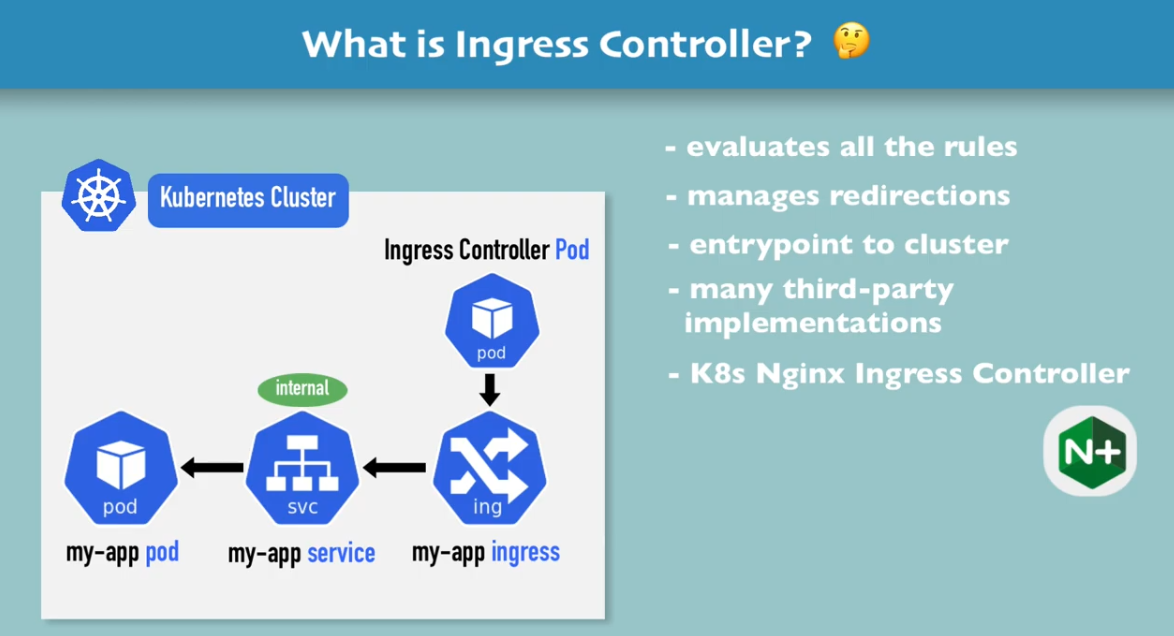
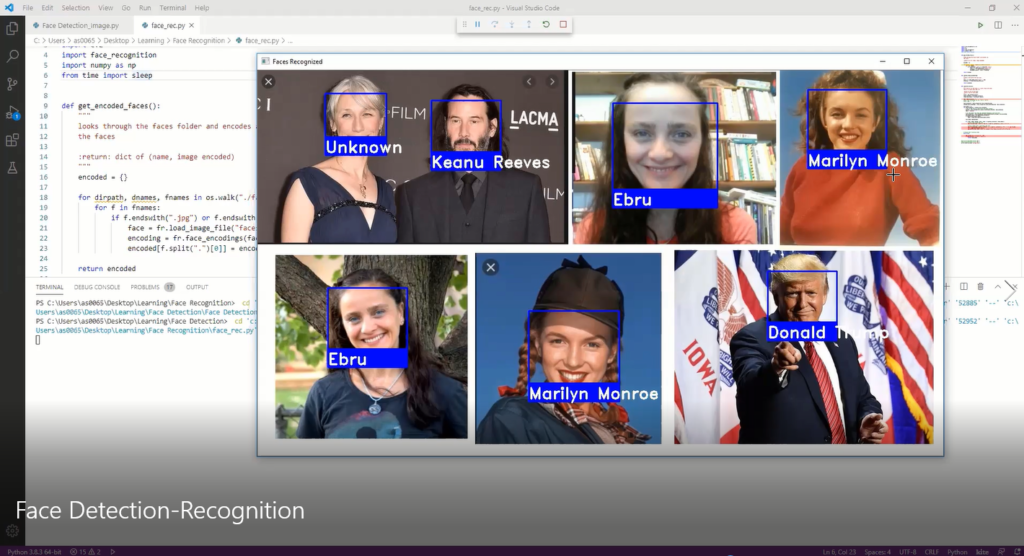
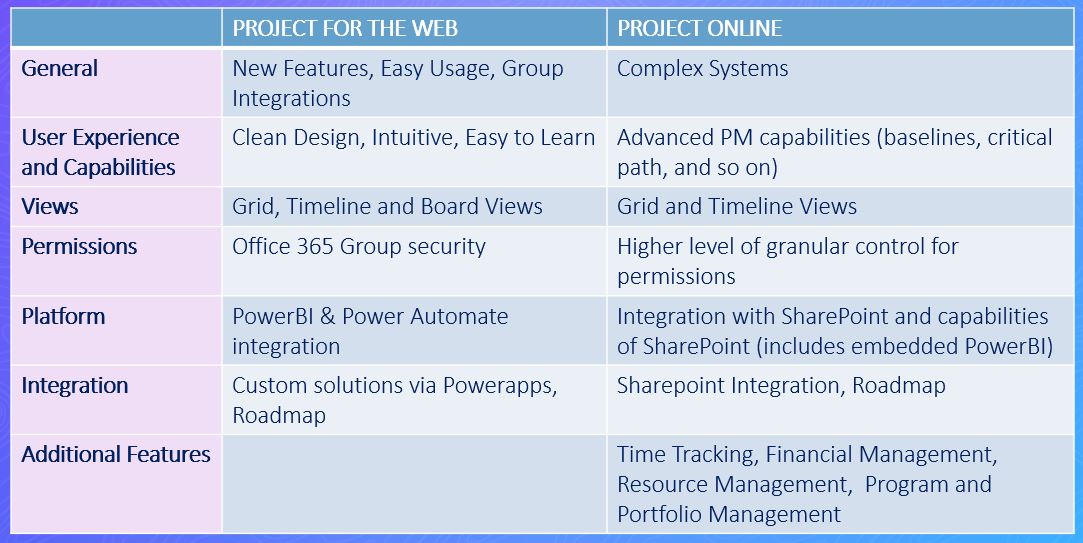
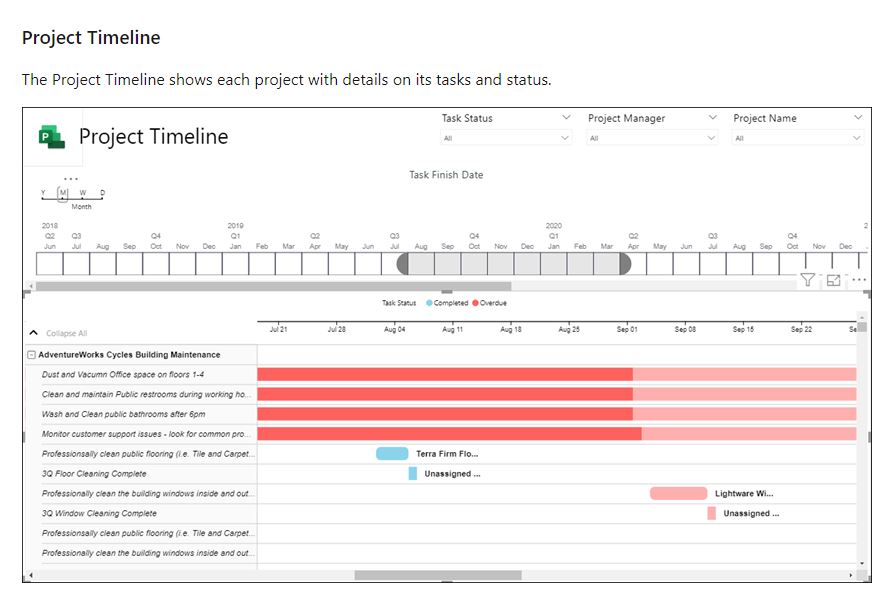
I’ve been wanting to organize my thoughts around Artificial Intelligence and Machine Learning and their impact on our lives for a while now, and my 15-mile bike ride this morning inspired me just to do that.
We are living in very exciting times. Finally, we have enough data that’s good quality and labeled, we have enough space and compute power so we can start enjoying the fruits of many decades of hard work, in terms of real life applications of AI & ML.
From Siri to Google Assistant, from Autonomous Vehicles to Robotics, AI is part of our day-to-day life.
There are a lot discussions about the potential dangers of AI, and rightly so. I’m cautiously optimistic. Like many tools we invent and use; AI can be helpful or harmful. A knife itself is not dangerous, but it can be in the wrong hands with harmful intentions. It can also look like a brush of a talented painter in the hands of a passionate chef!

One fear that seems to come up over and over again is the fear of AI being “better than humans”, better than us. How dare they?! 🙂 With personal experience and humility, I can assure you; many things around us, whether machine or alive, are better than humans in so many different and stunning ways. A Tiger is infinitely better than us in running and surviving in the wild. An Eagle can see and recognize a mouse from a far distance, while gracefully flying over the clouds. A calculator can do crazy math in milliseconds. A vacuum is much better in cleaning and dusting the home than we are and a car can take us in distant places that we cannot go by simply walking. We are surrounded by things, beings, tools that are better than us in some way or another, and usually in many areas combined.
So we need to recognize and accept that, while being intelligent and proactive about the potential challenges and pitfalls. Even though, a knife is not inherently harmful, we need to be smart about not letting a 3 year old to play with it.
What became so obvious to me recently is that there’s definitely a huge cost of potential loss of opportunity, if we do not use these amazing technologies for the betterment of humanity. Can you imagine a life without electricity or the Internet? Would the human experience be better or worse without these technologies? There is a moral obligation to weigh these considerations.
One of my goals in life is to reduce human suffering; whether that’s the suffering of my own, my family, my friends, my colleagues, my neighbors, my community, my pets, fellow animals, the nature… Obviously, the bigger positive impact I can make, the better. So why not utilize the technology that’s available? Even if we can make an existing positive impact slightly better, slightly more efficient, less wasteful, faster, more available, more accessible… why not partner with technology to achieve these goals?

The possibilities of correctly applied AI in the following domains excite me the most:
Education: Understanding the Process of Learning and Personalized Education. Imagine helping a young child to learn better, in the way that he or she is wired and understands better. Imagine helping young professionals to advance in their fields, in a personalized way. I always thought that before anything else, Education comes first! I am looking forward to seeing how we can improve our lives in this area with the help of technology (in whatever form it comes).
Healthcare: Specifically in diagnosis, personalized treatment, drug discovery and discovery in general. AI and technology can provide drastically different; a much more positive and trusting relationship with the hospitals, our doctors and other partners in the medical field.
Mental Health: Understanding Human Mind and Psychology is no small task. We can discover hidden patterns and trends and work our way to a happier existence!
I have a few personal ideas on how we can utilize Computer Vision and AI to reduce mental stress and suffering and improve general well being. More to come on that in my future blogs… 🙂
Discovery, Exploration & Inspiration: I believe one of the most interesting applications of AI is to recognize or expose the patterns that we are not able to see. Whatever your domain is, AI can help you explore more deeply and inspire you.
We cannot finish this blog without talking about the “bias”. AI bias is an anomaly in the output of machine learning algorithms. Personally, I don’t think we will ever have any AI without any bias. Because the whole system is built by humans and humans have biases! And who can’t tell that certain bias is healthy and needed. Let’s consider 2 situations.
In one, there’s a baby is in a building that’s on fire. A machine learning or an AI algorithm without any bias might find several adults risking their lives to save the baby illogical. If all lives are equal, why is it a better decision to risk multiple humans lives to save a youngster; especially considering over population?
In second situation, we have 85 year old person having a heart transplant. A machine learning or an AI algorithm without any bias might find that decision illogical. Wasting time and resources on already an older person when those resources can be used to improve or even save many other younger and healthier people with better chances.

As you can see, these are very hard, moral questions that we will have to face working with machine learning and AI. I believe the best approach is to keep getting involved, keep having open conversations and discussions at every level; from researchers to technology leaders, from students to cashiers at the grocery store. These technologies will be affecting all of us in varying degrees and inclusiveness is going to help us cover as much areas as possible that we might be missing otherwise. People from different background and culture will bring new data, new ideas and discussion points to the table.
I do have a few ideas about bias detection that I’m researching, keep tuning in for new blog items!
As I said in the beginning, I am cautiously optimistic. I’m super excited about the possibilities of human journey evolving on the path of having helpful data and information that allows us to take the right actions versus manipulation, in favor of responsible AI that empowers humanity versus controlling it. Freedom over Slavery, Abundance over Scarcity, Innovation over Status Quo. Good over Evil!
I’ve always been fascinated with Consciousness. During my college years, I came across David Chalmers‘ “The Conscious Mind” book in the library, which explores The Easy and The Hard Problem of Consciousness. Even with my very limited English at the time, I thought it was full of fundamental questions about human existence. I think AI can help us explore not only our physical body, brain and consciousness, but also our environment and Nature in general in new, exciting and powerful ways.
I would like to finish this blog with another question: Is there a chance of AI becoming self-conscious and sentient? I asked this question to my meditation teacher, and his answer was: “I don’t think much about AI. If it becomes conscious, cool. But really most humans are just machines on autopilot, so what’s the difference?”
What do you think?

Learn more about Ethical Decision Making
Thanks for sticking around and checking this page out. As a bonus, here’s a very cute and fascinating video from OpenAI on how AI learns.