There are so many great resources to learn more about AWS solutions and offerings.
I thought this youtube video was an excellent introduction. It maps the traditional architecture to AWS. Check it out:
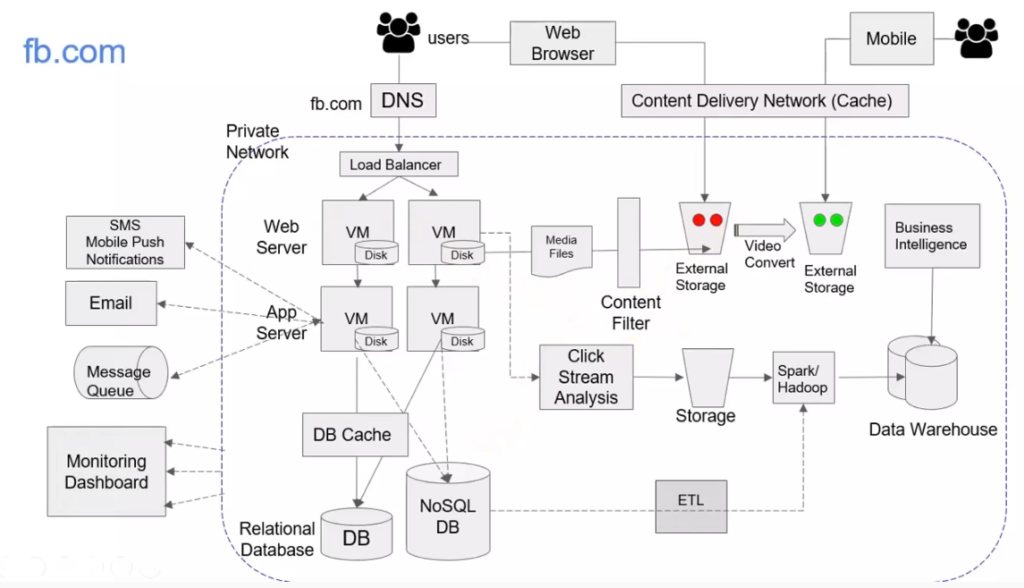
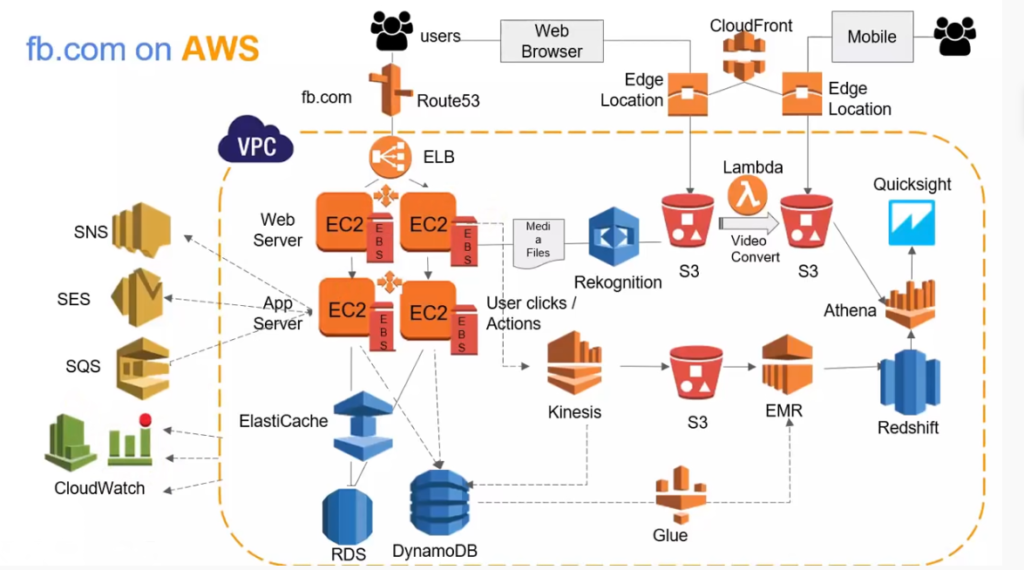
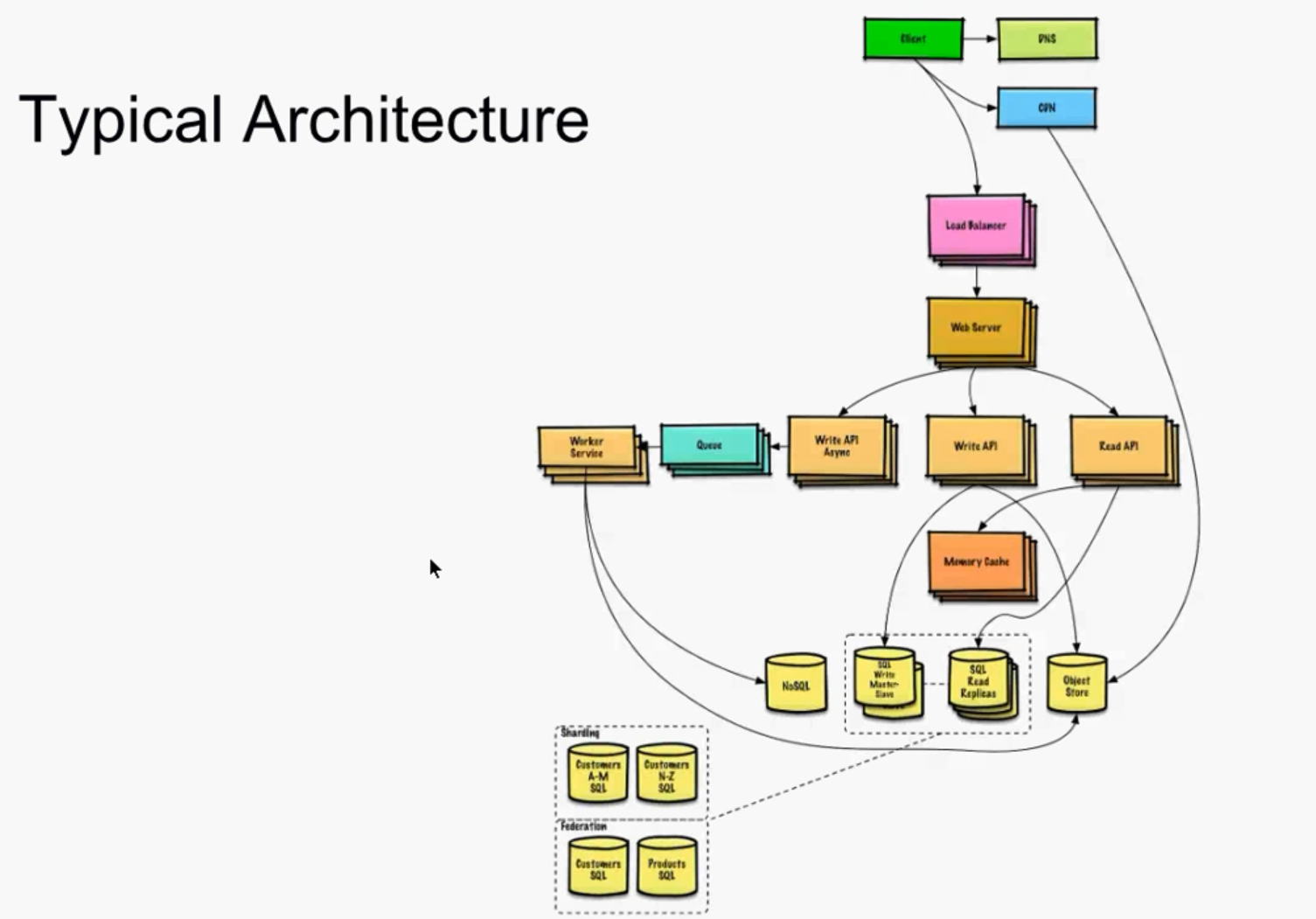
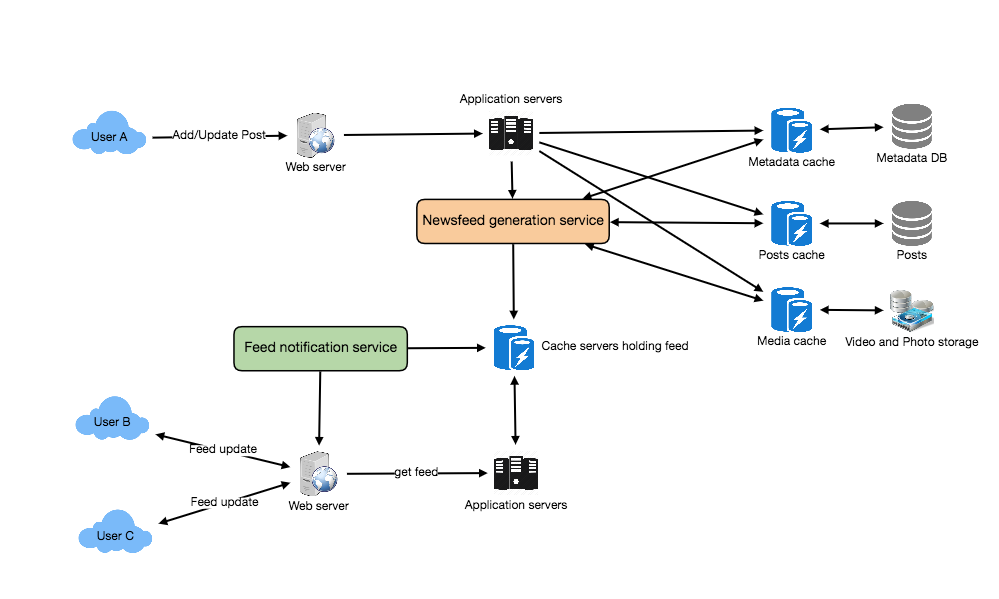
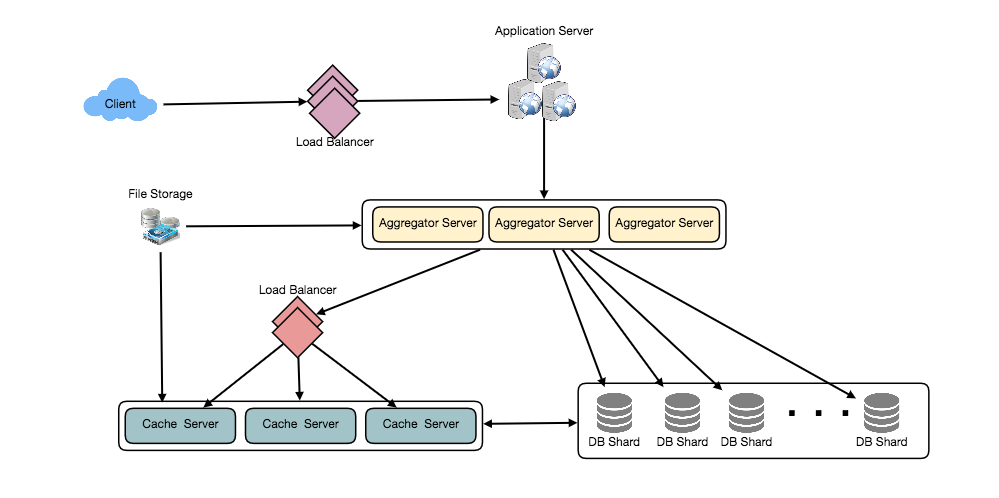
Here’s FB architecture with traditional terminologyHere’s FB on AWS
AWS has one of the best documentations out there, so for any questions, this is the most reliable resources to go to: https://docs.aws.amazon.com/index.html
This is also a great resource for frameworks and best practices:
Unless you’ve been living on another planet, you’ve probably heard about Amazon’s Alexa. It is a pretty cool cloud-based voice service.
What can you do with Alexa?
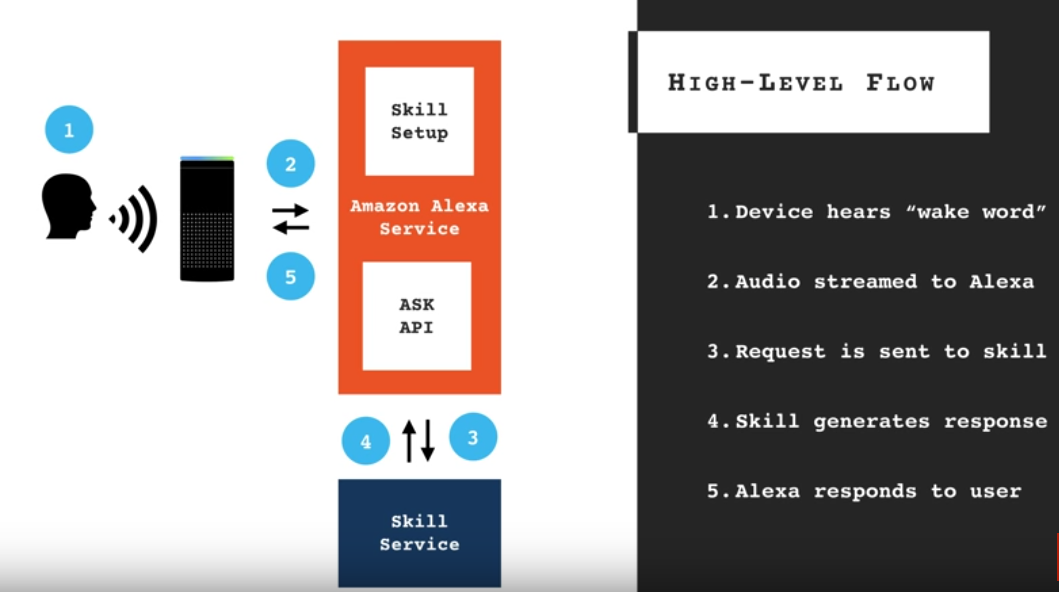
I’ve been looking into the technology behind Alexa. At the high level, it’s simple, yet elegant.
I believe Alexa uses SSML; Speech Synthesis Markup Language, when converting Text to Speech (TTS); because she sounds very conversational; rather than a robot reading the text word by word.
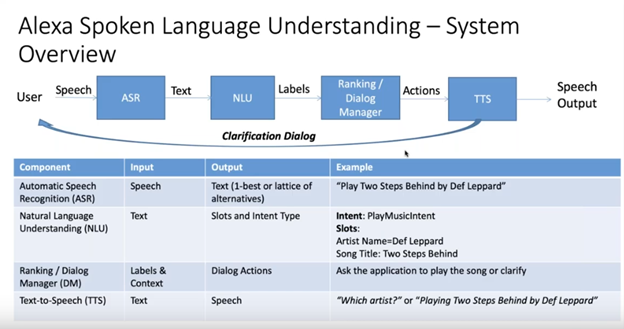
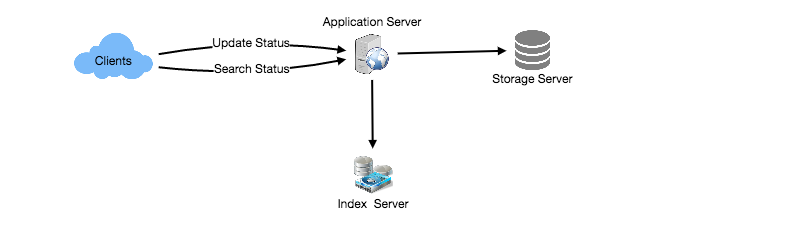
Here are a few more technical diagrams of how it works at the high level:
ASR Overview
I thought that the developing an Alexa Skill was straight forward and user friendly; especially if you have used any ML/AI tools. Navigation and setup look similar to others.
I created a few new test skills by using existing templates and added new custom intents. It was fun and I can see by a little bit of creativity, some great skills can be added to this fun smart tool!
Please watch my demo down below:
First skill is a game template where I added new custom intents.
Second skill is calling a fun external API that returns the number of astronauts currently in space and their names. 🙂http://api.open-notify.org/astros.json
Another interesting video about “Lessons Learned Growing Alexa” and a few fun capabilities/skills that the Amazon Team discusses.
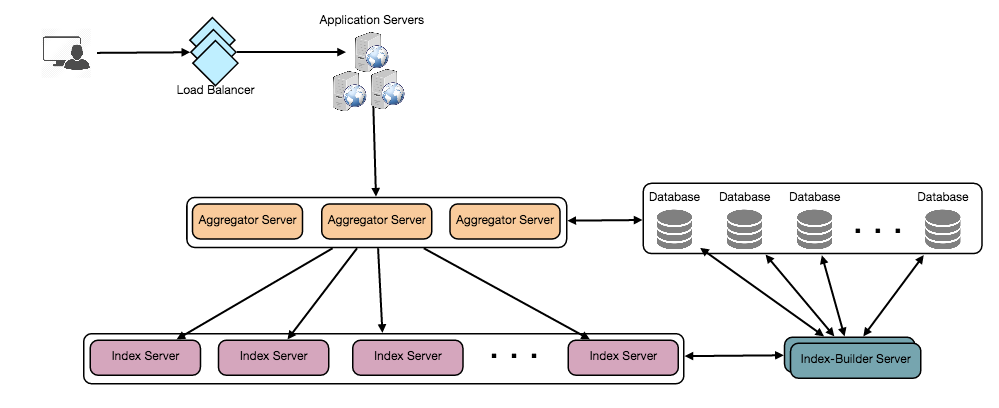
Bonus point: If you’d like to do a deep dive and create Alexa Skills with serverless backend, this youtube video should help and here are some more technical diagrams from the presentation:
Build a Serverless Back End for Your Alexa-Based Voice InteractionsIAM Management Flow
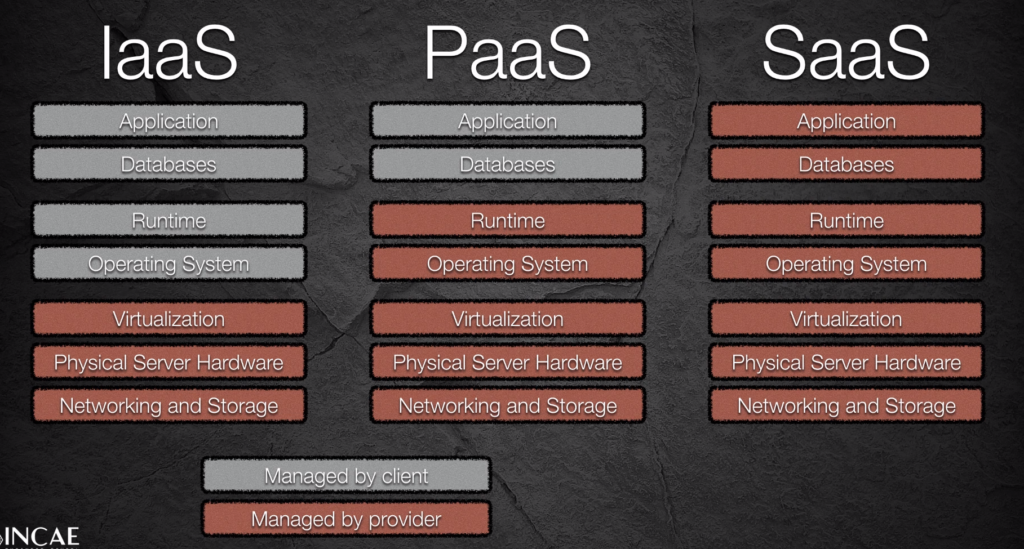
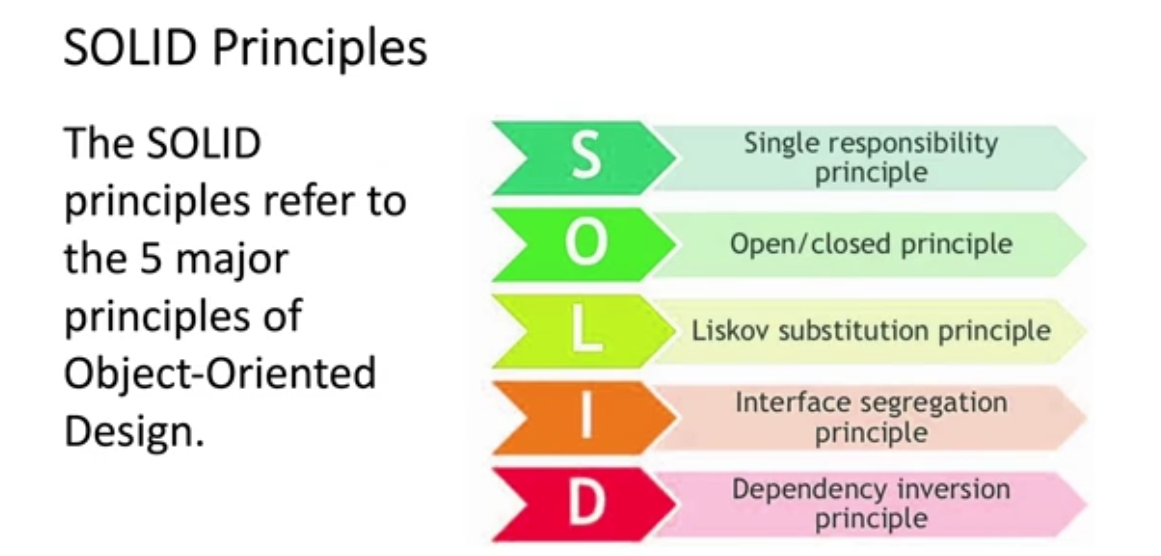
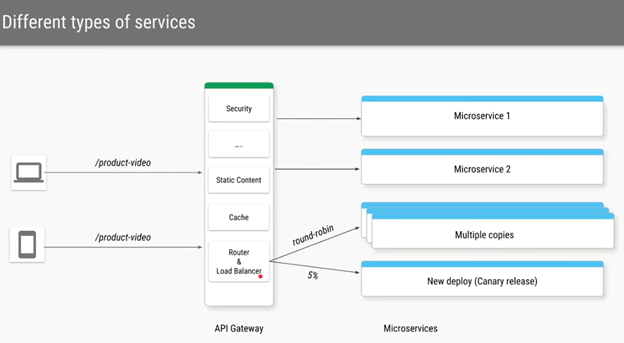
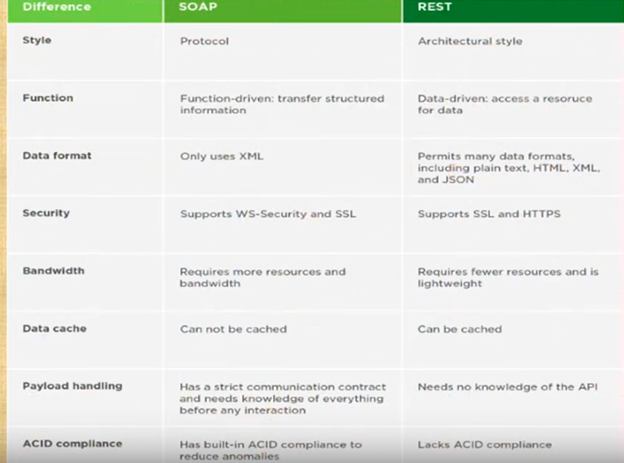
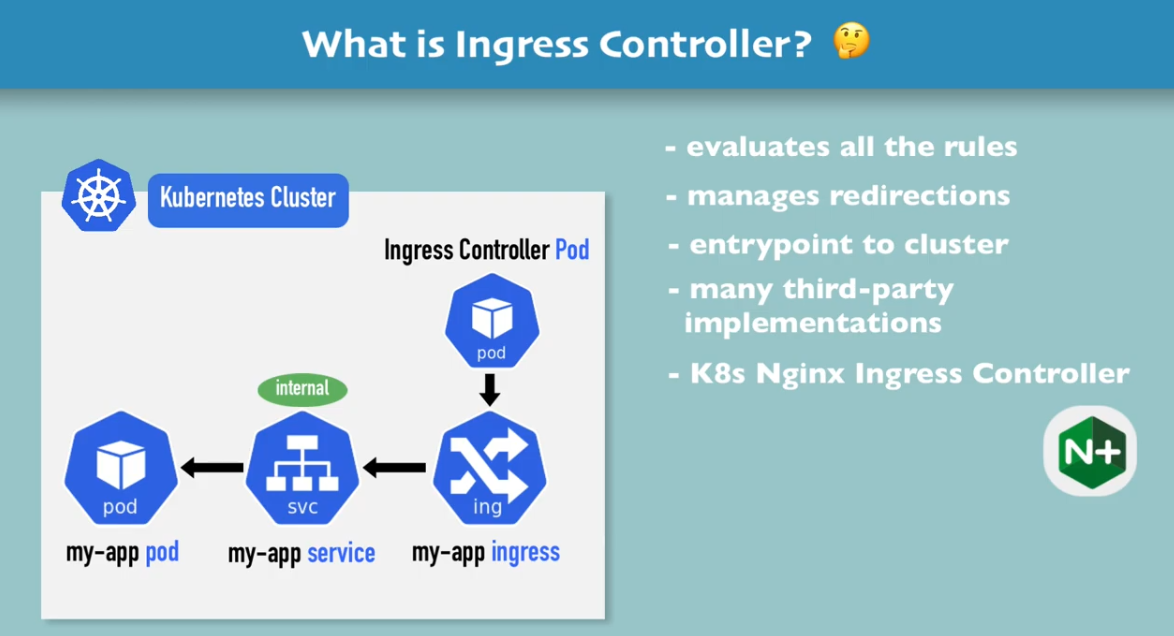
AWS – Well ArchitectedInfrastructure as a Service (i.e. AWC EC2), Platform as a Service (i.e. AWS Lamda or GCP App Engine, Software as a Service (i.e. Google Email)Resiliency Design Patterns (+Retry) ACID PropertiesSOLID Principles in Software Architecture
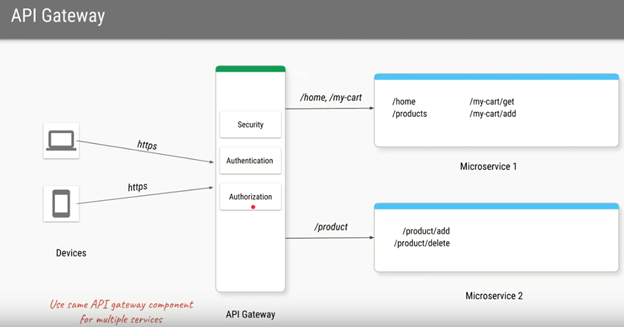
API Definition SampleLoad Balancer / OSI / Communication Protocol Layers
LOAD BALANCING METHODS
There is a variety of load balancing methods, which use different algorithms for different needs.
Least Connection Method — This method directs traffic to the server with the fewest active connections. This approach is quite useful when there are a large number of persistent client connections which are unevenly distributed between the servers.
Least Response Time Method — This algorithm directs traffic to the server with the fewest active connections and the lowest average response time.
Least Bandwidth Method – This method selects the server that is currently serving the least amount of traffic measured in megabits per second (Mbps).
Round Robin Method — This method cycles through a list of servers and sends each new request to the next server. When it reaches the end of the list, it starts over at the beginning. It is most useful when the servers are of equal specification and there are not many persistent connections.
Weighted Round Robin Method — The weighted round-robin scheduling is designed to better handle servers with different processing capacities. Each server is assigned a weight (an integer value that indicates the processing capacity). Servers with higher weights receive new connections before those with less weights and servers with higher weights get more connections than those with less weights.
IP Hash — Under this method, a hash of the IP address of the client is calculated to redirect the request to a server.
Optimise processes and increase output/products/services using the same resources (Vertical scaling)
Preparing before hand during non-peak hours (Pre processing / CRON job)
Keep backups and avoid single point failure (Replications / Master-Slave )
Hire more resources (Horizontal scaling)
Manage resources based on the business needs (7 pizza chef, 3 garlic bread) and separate duties, entities (Microservices)
Distributed Systems / Positioning. Have multiple DataCenters for Disaster Recovery and Business Continuity (maybe even in different countries). This might also help with response time (depending on how the data is routed) + Fault Tolerance.
LoadBalancing can help to be more efficient with using the resources (Send the customer orders to Pizza Shop1 vs. Pizza Shop2; based on the order, location, wait time etc).
Decouple the system; separate out the concerns… Order Processing, Processing, Delivery etc.
Put Metrics in place (Reporting, Analytics, Auditing, Machine Learning)
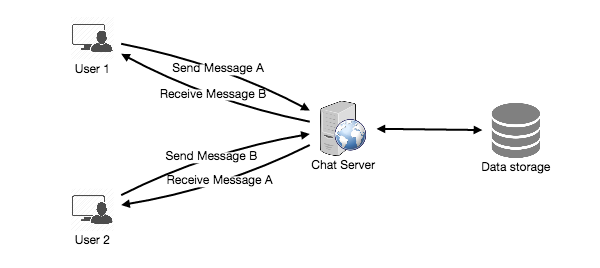
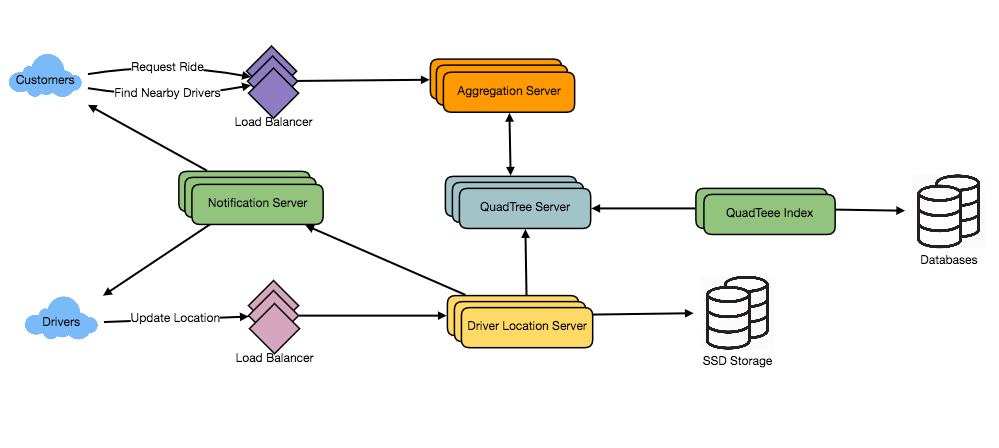
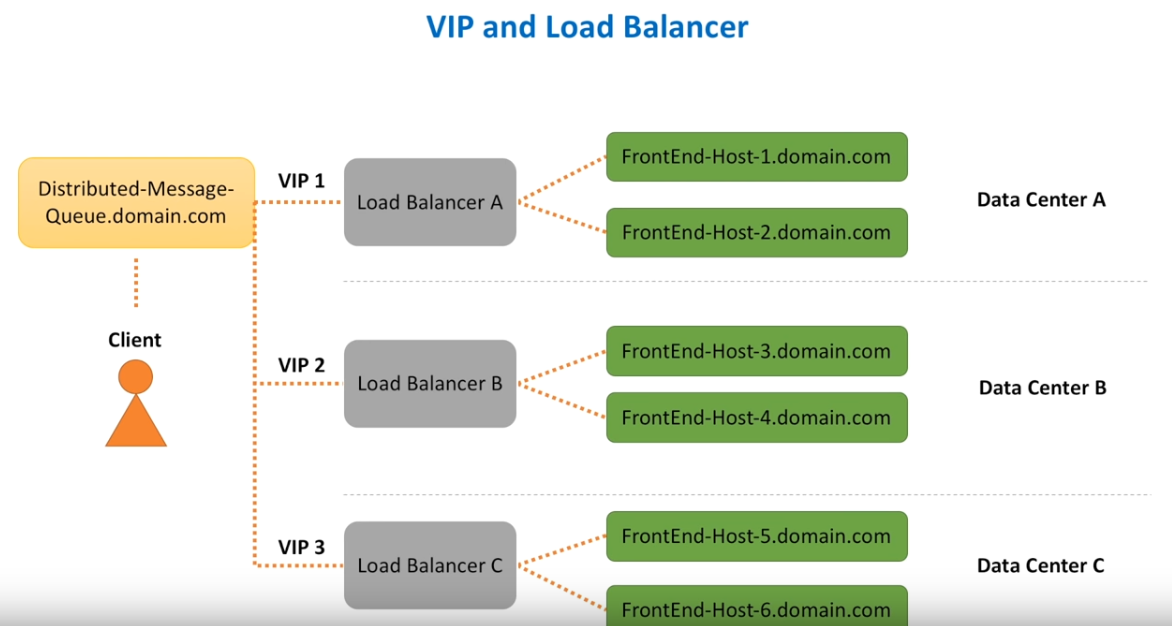
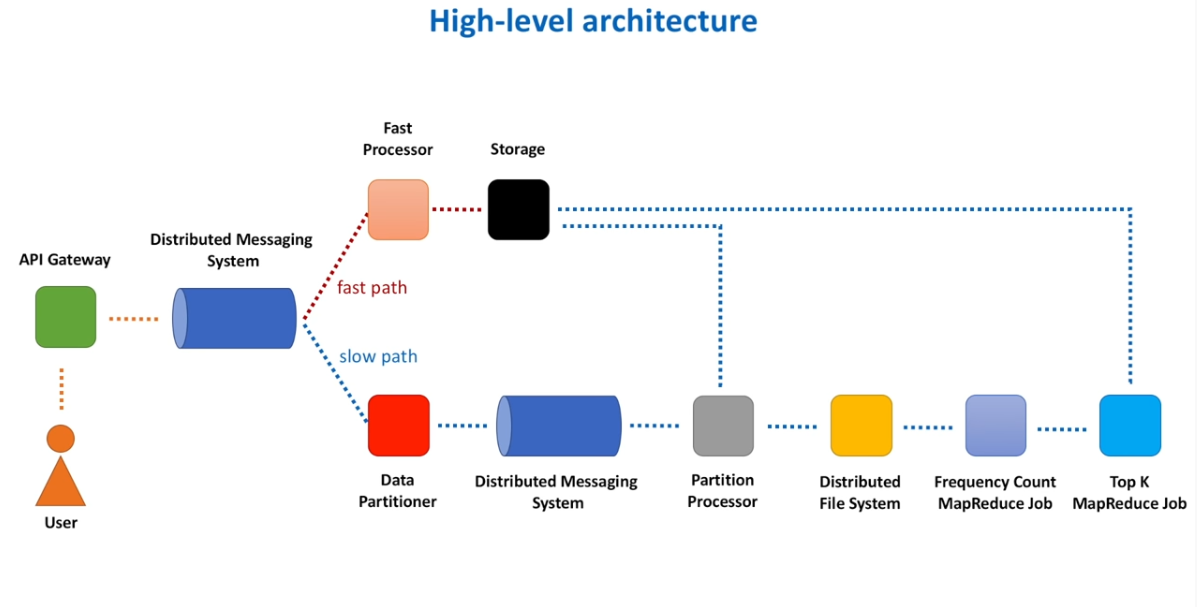
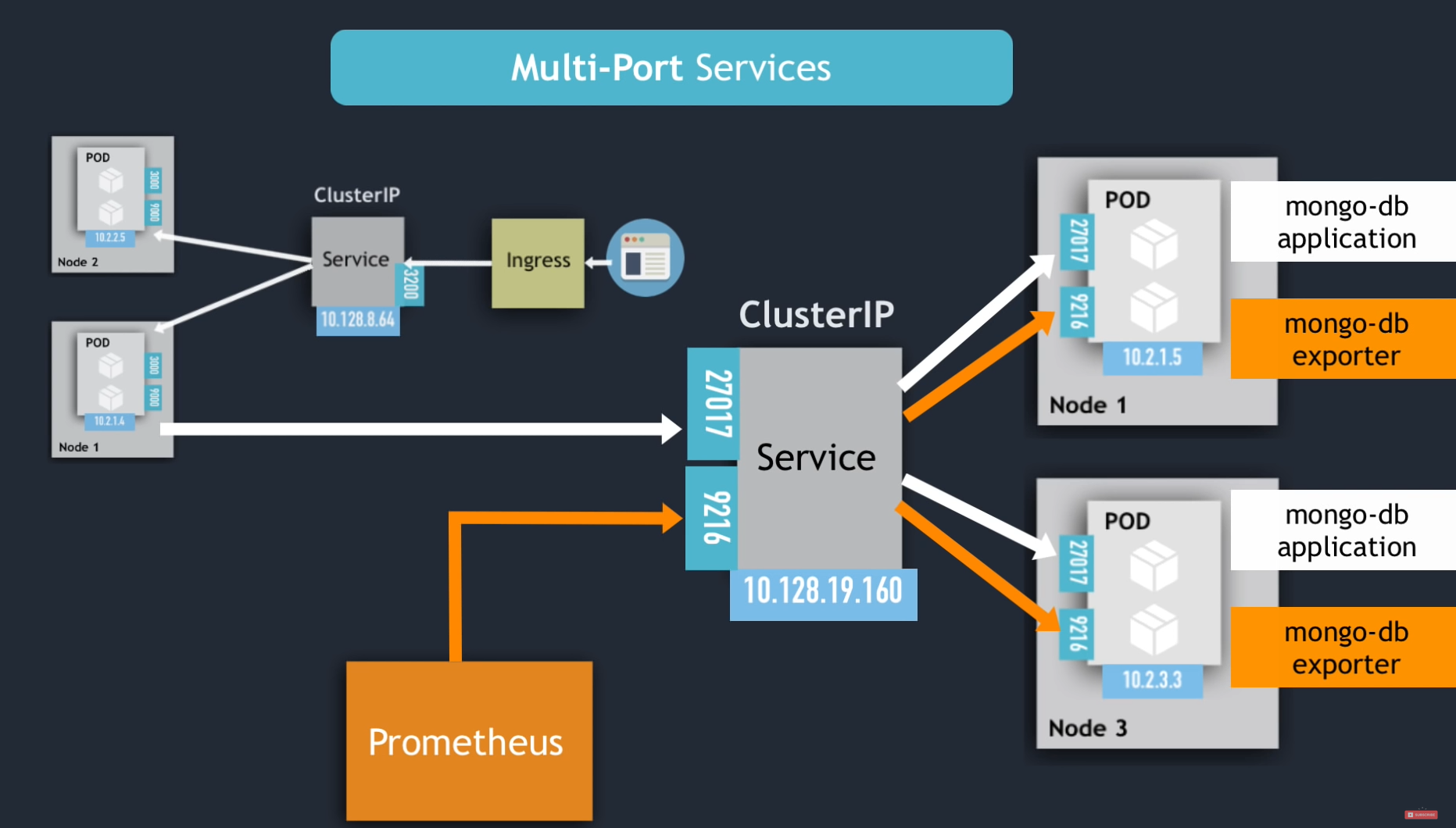
Distributed Message Queue – Problem StatementFunctional & Non-Functional RequirementsHigh Level Architecture – Distributed Message QueueVirtual IP and Load BalancerFrontEnd Service
FRONTEND SERVICE COMPONENTS
Request Validation
Required parameters are present
Data falss within an acceptable range
Authentication/Authorization
Authentication is the process of validating the identity of a user or a service
Authorization is the process of determining whether or not a specific actor is permitted to take action
TLS Termination
TLS is a protocol that aims to provide privacy and data integration
TLS termination refers to the process of decrypting request and passing on an unencrypted request to the back end service
SSL on the load balancer is expensive
Termination is usually handled by not a FrontEnd service itself but a separate TLS HTTP proxy that runs as a process on the same host
Server-side encryption
Messages are encrypted as soon as FrontEnd receives them
Messages are stored in encrypted form and FrontEnd decrypts messages only when they are sent back to a consumer
Caching
Cache stores copies of source data
It helps reduce load to backend services, increases overall system throughput and availability, decreases latency
Stores metadata information about the most actively used queues
Stores user identity information to save on calls to auth services
Rate limiting (Throttling)
Throttling is the process of limiting the number of requests you can submit to a given operation in a given amount of time
Throttling protects the web service from being overwhelmed with requests
Leaky bucket algorithm is one of the most famous
Request dispatching
Responsbile for all the activities associated with sending requests to backend services (client management, response handling, resource isolation, etc)
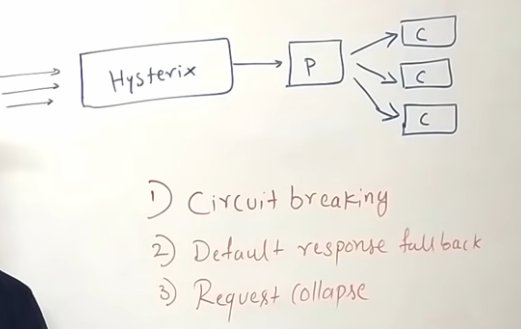
Bulkhead pattern helps to isolate elements of an application into pools so that if one fails, the others will continue function
Circuit Breaker pattern prevents an application from repeatedly trying to execute an operation that’s likely to fail
Request de-duplication
May occur when a response from a successful sendMessage request failed to reach a client
Lesser an issue for “at least once” delivery semantics, a bigger issue for “exactly once” and “at most once” delivery semantics
Caching is usually used to store previously seen request ids
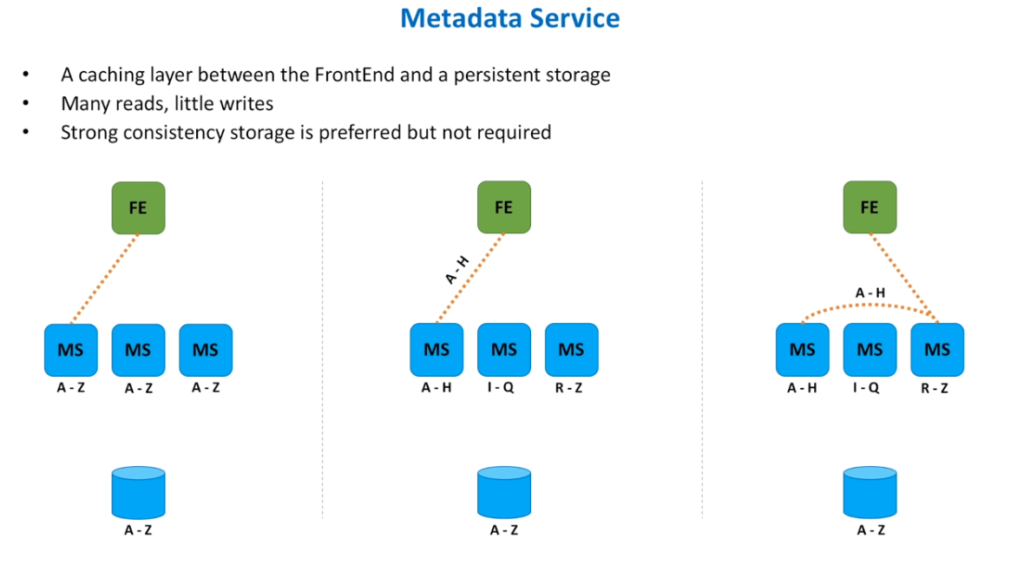
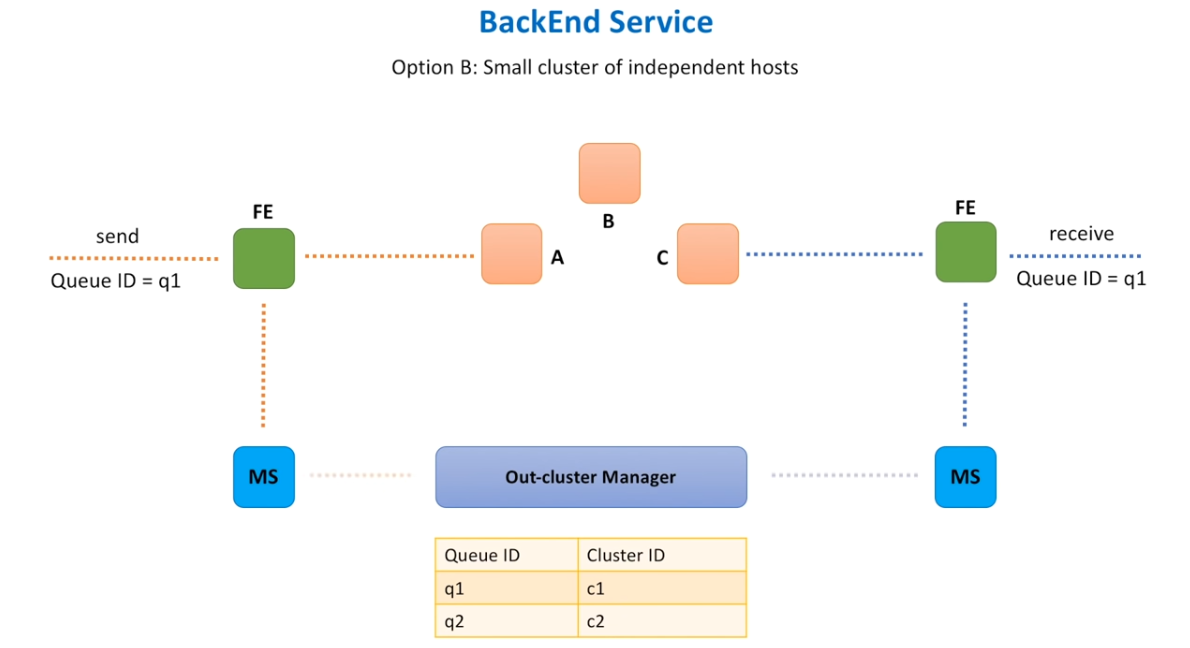
MetaData Service – Sharding BackEnd ServiceOption A – Leader-FollowerOption B – Small Cluster of Independent HostsComparison of Cluster ManagersOther Consideration for Distributed Message Queue
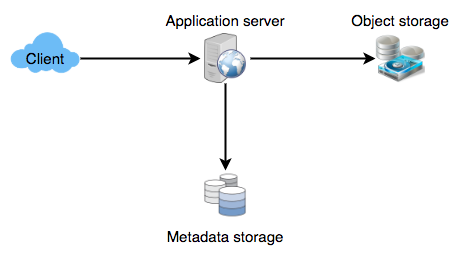
Capacity Estimation and Constraints for Tiny URL #
Our system will be read-heavy. There will be lots of redirection requests compared to new URL shortenings. Let’s assume a 100:1 ratio between read and write.
Traffic estimates: Assuming, we will have 500M new URL shortenings per month, with 100:1 read/write ratio, we can expect 50B redirections during the same period: 100 * 500M => 50B
What would be Queries Per Second (QPS) for our system? New URLs shortenings per second: 500 million / (30 days * 24 hours * 3600 seconds) = ~200 URLs/s
Considering 100:1 read/write ratio, URLs redirections per second will be: 100 * 200 URLs/s = 20K/s
Storage estimates: Let’s assume we store every URL shortening request (and associated shortened link) for 5 years. Since we expect to have 500M new URLs every month, the total number of objects we expect to store will be 30 billion: 500 million * 5 years * 12 months = 30 billion
Let’s assume that each stored object will be approximately 500 bytes (just a ballpark estimate–we will dig into it later). We will need 15TB of total storage: 30 billion * 500 bytes = 15 TB https://js.educative.io/static/runjs/index.html?id=ULRhG
Bandwidth estimates: For write requests, since we expect 200 new URLs every second, total incoming data for our service will be 100KB per second: 200 * 500 bytes = 100 KB/s
For read requests, since every second we expect ~20K URLs redirections, total outgoing data for our service would be 10MB per second: 20K * 500 bytes = ~10 MB/s
Memory estimates: If we want to cache some of the hot URLs that are frequently accessed, how much memory will we need to store them? If we follow the 80-20 rule, meaning 20% of URLs generate 80% of traffic, we would like to cache these 20% hot URLs.
Since we have 20K requests per second, we will be getting 1.7 billion requests per day: 20K * 3600 seconds * 24 hours = ~1.7 billion
To cache 20% of these requests, we will need 170GB of memory. 0.2 * 1.7 billion * 500 bytes = ~170GB
One thing to note here is that since there will be many duplicate requests (of the same URL), our actual memory usage will be less than 170GB.
** High-level estimates:** Assuming 500 million new URLs per month and 100:1 read:write ratio, following is the summary of the high level estimates for our service:
Let’s estimate how much data will be going into each table and how much total storage we will need for 10 years.
User: Assuming each “int” and “dateTime” is four bytes, each row in the User’s table will be of 68 bytes: UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + DateOfBirth (4 bytes) + CreationDate (4 bytes) + LastLogin (4 bytes) = 68 bytes
If we have 500 million users, we will need 32GB of total storage. 500 million * 68 ~= 32GB
Photo: Each row in Photo’s table will be of 284 bytes: PhotoID (4 bytes) + UserID (4 bytes) + PhotoPath (256 bytes) + PhotoLatitude (4 bytes) + PhotoLongitude(4 bytes) + UserLatitude (4 bytes) + UserLongitude (4 bytes) + CreationDate (4 bytes) = 284 bytes
If 2M new photos get uploaded every day, we will need 0.5GB of storage for one day: 2M * 284 bytes ~= 0.5GB per day For 10 years we will need 1.88TB of storage.
UserFollow: Each row in the UserFollow table will consist of 8 bytes. If we have 500 million users and on average each user follows 500 users. We would need 1.82TB of storage for the UserFollow table: 500 million users * 500 followers * 8 bytes ~= 1.82TB
Total space required for all tables for 10 years will be 3.7TB: 32GB + 1.88TB + 1.82TB ~= 3.7TB